Plabic tilingのためのRソースメモ

V <- matrix(0,13,18) F <- matrix(0,15,18) E <- matrix(0,18,18) V[1,c(12,14,7,3,4,5,6,10,8)] <- 1 V[2,c(14,7,16,11,5,6,8,10,12)] <- 1 V[3,c(14,7,16,9,8,11,10,15,12)] <- 1 V[4,c(14,2,16,11,9,13,12,10,15)] <- 1 V[5,c(14,2,16,11,15,13,6,18,12)] <- 1 V[6,c(14,2,16,4,15,6,18,17,13)] <- 1 V[7,c(1,2,16,15,4,6,17,8,18)] <- 1 V[8,c(1,2,3,4,5,6,17,8,18)] <- 1 V[9,c(1,2,3,4,6,5,10,12,8)] <- 1 V[10,c(1,2,16,4,5,6,8,12,18)] <- 1 V[11,c(14,2,16,4,5,6,8,10,12)] <- 1 V[12,c(14,2,16,4,15,6,12,18,8)] <- 1 V[13,c(14,2,16,11,10,15,6,12,8)] <- 1 theta <- (1:18) / 18 * 2 * pi x <- cbind(cos(theta),sin(theta)) Vx <- V %*% x plot(Vx,pch=20,col=1,asp=TRUE) F[1,c(12,2,14,10,3,4,5,6,8)] <- 1 F[2,c(14,7,16,6,4,5,8,12,10)] <- 1 F[3,c(14,16,11,6,10,7,15,8,12)] <- 1 F[4,c(14,2,11,16,9,15,8,10,12)] <- 1 F[5,c(14,2,11,16,15,6,13,12,10)] <- 1 F[6,c(14,13,16,2,4,6,15,18,12)] <- 1 F[7,c(14,2,16,4,8,17,15,6,18)] <- 1 F[8,c(1,2,16,4,5,17,6,8,18)] <- 1 F[9,c(1,2,3,4,5,6,8,18,12)] <- 1 F[10,c(1,2,5,16,4,6,8,10,12)] <- 1 F[11,c(1,2,16,12,15,4,6,8,18)] <- 1 F[12,c(14,2,4,16,12,6,8,5,18)] <- 1 F[13,c(14,12,2,4,16,10,15,6,8)] <- 1 F[14,c(14,2,16,10,11,5,6,8,12)] <- 1 F[15,c(14,6,2,11,18,15,6,8,12,16)] <- 1 Fx <- F %*% x points(Fx,pch=20,col=2) E[1,c(2,10,4,3,16,5,6,8,12)] <- 1 E[2,c(14,2,7,6,8,4,5,10,12)] <- 1 E[3,c(14,16,4,11,5,6,8,10,12)] <- 1 E[4,c(10,12,14,6,2,7,11,16,8)] <- 1 E[5,c(14,6,8,16,9,11,15,12,10)] <- 1 E[6,c(14,2,15,16,13,11,8,10,12)] <- 1 E[7,c(14,16,11,2,10,6,15,18,12)] <- 1 E[8,c(14,12,2,8,16,15,13,6,18)] <- 1 E[9,c(14,2,17,16,4,12,15,18,6)] <- 1 E[10,c(1,2,16,6,14,4,15,8,18)] <- 1 E[11,c(17,1,2,16,4,6,8,12,18)] <- 1 E[12,c(1,2,3,4,5,6,8,16,18)] <- 1 E[13,c(1,2,4,12,18,5,6,8,10)] <- 1 E[14,c(1,14,16,2,4,5,6,8,12)] <- 1 E[15,c(2,16,5,15,4,6,18,8,12)] <- 1 E[16,c(14,2,12,4,16,10,6,8,18)] <- 1 E[17,c(14,10,16,2,5,6,15,8,12)] <- 1 E[18,c(14,16,2,4,11,15,12,6,8)] <- 1 Ex <- E %*% x points(Ex, pch=20,col=3) VFE <- rbind(V,F,E) col.v <- c(rep(4,length(V[,1])),rep(5,length(F[,1])),rep(6,length(E[,1]))) X <- VFE %*% x distmat <- as.matrix(dist(VFE, method="manhattan")) el <- which(distmat==2,arr.ind=TRUE) # 3角形は、V,F,Eを1つずつ頂点とするので、適切なトリオを選ぶ tris <- matrix(0,0,3) for(i in 1:length(V[,1])){ for(j in 1:length(F[,1])){ for(k in 1:length(E[,1])){ tmp0 <- c(i,j+13,k+13+15) tmp <- distmat[tmp0,tmp0] diag(tmp) <- 2 if(sum((tmp-2)^2) == 0){ tris <- rbind(tris,tmp0) } } } } #tris <- rbind(c(1,1,2),c(1,2,2),c(2,2,3),c(2,14,3),c(2,3,4),c(3,3,5),c(3,4,5),c(4,4,6),c(4,5,6),c(5,5,7),c(5,15,7),c(5,6,8),c(6,6,9),c(6,7,9),c(7,7,10),c(7,11,10),c(7,11,11),c(7,8,11),c(8,8,12),c(8,9,12),c(9,9,13),c(9,10,13),c(9,1,1)) #tris[,2] <- tris[,2] + 13 #tris[,3] <- tris[,3] + 13 + 15 tri.col <- rep(0,length(tris[,1])) for(i in 1:length(tris[,1])){ tmp <- VFE[tris[i,],] if(prod(apply(tmp,2,sum) -1) == 0){ tri.col[i] <- 2 }else{ tri.col[i] <- 3 } } ######## # Plabic graph G* par(mfcol=c(2,2)) plot(X, pch=20,cex=2,col=col.v,asp=TRUE) segments(X[el[,1],1], X[el[,1],2],X[el[,2],1],X[el[,2],2]) for(i in 1:length(tris[,1])){ polygon(X[tris[i,c(1,2,3,1)],1],X[tris[i,c(1,2,3,1)],2],col=tri.col[i]) } points(X,pch=20,col=col.v,cex=2) ######### # Vの3角形はうまく描ける plot(X, pch=20,cex=2,col=col.v,asp=TRUE) segments(X[el[,1],1], X[el[,1],2],X[el[,2],1],X[el[,2],2]) for(i in 1:length(tris[,1])){ polygon(X[tris[i,c(1,2,3,1)],1],X[tris[i,c(1,2,3,1)],2],col=tri.col[i]) } distmat.v <- as.matrix(dist(V,method="manhattan")) el.v <- which(distmat.v==4,arr.ind=TRUE) points(Vx,pch=20) segments(Vx[el.v[,1],1],Vx[el.v[,1],2],Vx[el.v[,2],1],Vx[el.v[,2],2],lw=2) ########## # Fの3-valentグラフはこの方法ではうまく描けない # 組み合わせ的距離では、Vを介して多数のFペアの距離が同じになるから plot(X, pch=20,cex=2,col=col.v,asp=TRUE) segments(X[el[,1],1], X[el[,1],2],X[el[,2],1],X[el[,2],2]) for(i in 1:length(tris[,1])){ polygon(X[tris[i,c(1,2,3,1)],1],X[tris[i,c(1,2,3,1)],2],col=tri.col[i]) } distmat.f <- as.matrix(dist(F,method="manhattan")) el.f <- which(distmat.f==4,arr.ind=TRUE) points(Fx,pch=20) segments(Fx[el.f[,1],1],Fx[el.f[,1],2],Fx[el.f[,2],1],Fx[el.f[,2],2]) ########## # Eをつないだ箙はこの方法ではうまく描けない # 組み合わせ的距離では、Vを介して多数のEペアの距離が同じになるから plot(X, pch=20,cex=2,col=col.v,asp=TRUE) segments(X[el[,1],1], X[el[,1],2],X[el[,2],1],X[el[,2],2]) for(i in 1:length(tris[,1])){ polygon(X[tris[i,c(1,2,3,1)],1],X[tris[i,c(1,2,3,1)],2],col=tri.col[i]) } distmat.e <- as.matrix(dist(E,method="manhattan")) el.e <- which(distmat.e==4,arr.ind=TRUE) points(Ex,pch=20) segments(Ex[el.e[,1],1],Ex[el.e[,1],2],Ex[el.e[,2],1],Ex[el.e[,2],2])
平面ネットワークのPlucker 座標
- n個の点が円周上に配置されているとする
- その内部円板に有向グラフがあるとき、適当な変形を加えることで、3-valent有向グラフに変えることができる
- このグラフをplanar circular directed graphと呼ぶ
- さらに、3-valent有向グラフを3-valent bipartite plabic グラフに変えることもできる
- このplanar circular directed graphの円周上の点はただ1本の辺に接続するというルールがあるので、すべての円周上の点は、湧き出し口か吸い込み口かのどちらかになる
- 今、湧き出し口の数がk個、吸い込み口の数がn-k個であり、円周上の点の数がnであるとする
- このグラフに
行列を定義することができる。Boundary measurement matrixと呼ぶ
- この行列は
であるので、この行列には、Plucker座標が定められる
- ちなみに、Plucker座標とは、
からk個の要素を取り出したときに(
通りの組合せが作れる)、それぞれの組について、Boundary measurement matrixの該当列を取り出すことで、
行列が取れるが、その
- さて、planar circular directed graphの場合に、Boundary measurement matrix (
の要素
として、湧き出し口頂点から1頂点 i を取り除き、その代わりに吸い込み口の頂点から1頂点 jを追加してできるk個の頂点の組合せを考えた時に、頂点iから湧き出して、頂点jに吸い込まれるようなパスの本数に相当する値
を考え、j番目が、湧き出し口のすべてより若いか、すべてより大きいか、湧き出し口の間に挟まれているか、さらには気にしている湧き出し口頂点 i番と比べて若いか大きいかによって、
- このとき、Plucker 座標の要素のすべてが非負になることが知られている
- その結果、planar circular networkはpositive grassmanian上の点に対応付けられる、という話がある
- このリンク先のペイパーでは、このPlucker座標が、k個の列の選び方に応じて、networkに取れる、ある種の正エッジ重みづけパス本数セットに関する値になっていることを示している
- 基本的には、正重みづけでの「取りうるパスの場合」に関する足し合わせであることから、すべてのPlucker座標が非負になる
- また、そのパス本数セットに相当する値の計算式は、内部にサイクルがなければ単純な式になり、サイクルがあると、有理式になるのだが、その様子が団代数・団変数と同じ挙動をすることも示せる
- そもそも、planar circular networkで小行列式が非交叉パスの取り方の場合分けと関係した非負の値がとれる(ただし、符号の考慮が必要)な話は、左列にあるn頂点から、右列にあるn頂点へのplanar directed graphがあったときに、非交叉パスの場合の数が符号を考えなくて良い小行列式で表されることが知られており、それをcircularに拡張した時に、湧き出し口・吸い込み口の相互位置関係に関して複雑になっている部分を符号操作で一般化したものになっている
- 内部のサイクルによる補正のことは忘れて、あるplanar circular networkがあって、そのBoundary measurement matrixを取り、そのPlucker 座標がすべて正になることを例で確かめてみよう
- こんなグラフ
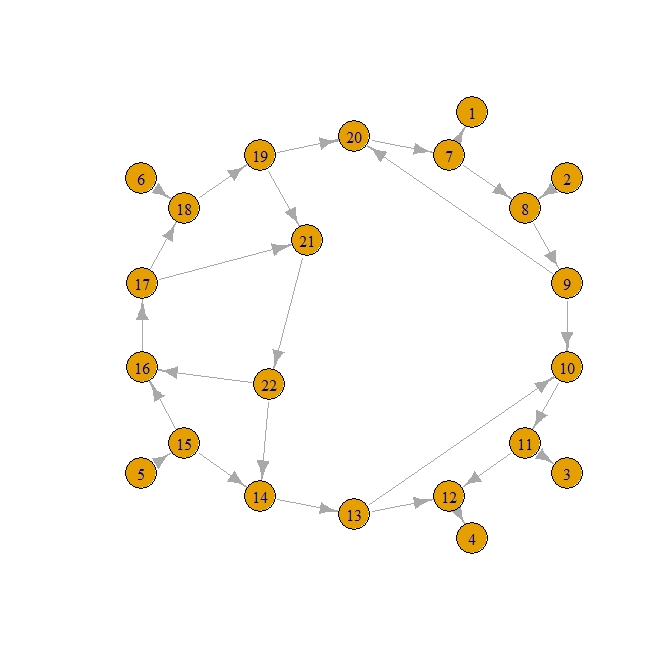
tmp <- c(7,1,2,8,11,3,12,4,5,15,6,18,7,8,8,9,9,10,10,11,11,12,13,12,14,13,15,14,15,16,16,17,17,18,18,19,19,20,20,7,9,20,13,10,19,21,21,22,22,14,22,16,17,21) el <- matrix(tmp,byrow=TRUE,ncol=2) library(igraph) g <- graph.edgelist(el) theta <- pi/2 - (1:14)/14 * 2 * pi theta. <- theta[c(1,2,5,6,9,12,1:14,13,9)] r <- c(rep(1,6),rep(0.8,14),rep(0.4,2)) coords <- cbind(cos(theta.),sin(theta.)) * r plot(g,layout = coords)
- 湧き出し口頂点は2,5,6で、吸い込み口頂点は1,3,4
- このBoundary measurement matrixは以下のようになる
# 頂点 iからjへのパスの数の列挙 paths <- list() for(i in 1:22){ paths[[i]] <- list() for(j in 1:22){ paths[[i]][[j]] <- all_simple_paths(g,i,j) } } A <- matrix(0,3,6) # 湧き出し口数 x 全周囲頂点数 の行列 sources <- c(2,5,6) # 湧き出し頂点ID for(i in 1:3){ # 湧き出し頂点ループ for(j in 1:6){ # 全周囲頂点ループ A[i,j] <- length(paths[[sources[i]]][[j]]) # i ---> j パス数列挙 btwn <- which((j-sources) * (sources[i] - sources) < 0) # i---j間の湧き出し頂点の判別 tmp.sign <- (-1)^length(btwn) # length(btwn)は i---j間湧き出し頂点数 A[i,j] <- A[i,j] * tmp.sign if(sources[i] == j){ A[i,j] <- 1 } } }
> A [,1] [,2] [,3] [,4] [,5] [,6] [1,] 1 1 1 1 0 0 [2,] -1 0 4 7 1 0 [3,] 1 0 -2 -3 0 1
-
- 1,2,3行目はそれぞれ、2,5,6湧き出し頂点に対応する
- 1行目は、2番頂点から、1,2,3,4,5,6頂点へのパスの場合の数。2と1,2,3,4,5,6の間には、湧き出し口が挟まれていないので、すべての値が正。湧き出し口5,6へのパスはなく、自身へのパスの数は1
- 2行目は、5番頂点から、1,2,3,4,5,6頂点のパスの場合の数。5と1の間には湧き出し口2(1個、奇数個)あるので、負。2,3,45,6と5の間には湧き出し口はないので正
- 3行目は、6番頂点から、1,2,3,4,5,6頂点のパスの場合の数。6と1の間には湧き出し口2,5(2個、偶数個)あるので、正。2,3,4と6の間には、湧き出し口5(1個、奇数個)あるので負(ただし、0は0)
- すべての組合せについて小行列式を計算して表示してみると正になっている
library(gtools) cmb <- combinations(6,3) for(i in 1:length(cmb[,1])){ print("cmb") print(cmb[i,]) print(det(A[,cmb[i,]])) }
> for(i in 1:length(cmb[,1])){ + print("cmb") + print(cmb[i,]) + print(det(A[,cmb[i,]])) + } [1] "cmb" [1] 1 2 3 [1] 2 [1] "cmb" [1] 1 2 4 [1] 4 [1] "cmb" [1] 1 2 5 [1] 1 [1] "cmb" [1] 1 2 6 [1] 1 [1] "cmb" [1] 1 3 4 [1] 4 [1] "cmb" [1] 1 3 5 [1] 3 [1] "cmb" [1] 1 3 6 [1] 5 [1] "cmb" [1] 1 4 5 [1] 4 [1] "cmb" [1] 1 4 6 [1] 8 [1] "cmb" [1] 1 5 6 [1] 1 [1] "cmb" [1] 2 3 4 [1] 2 [1] "cmb" [1] 2 3 5 [1] 2 [1] "cmb" [1] 2 3 6 [1] 4 [1] "cmb" [1] 2 4 5 [1] 3 [1] "cmb" [1] 2 4 6 [1] 7 [1] "cmb" [1] 2 5 6 [1] 1 [1] "cmb" [1] 3 4 5 [1] 1 [1] "cmb" [1] 3 4 6 [1] 3 [1] "cmb" [1] 3 5 6 [1] 1 [1] "cmb" [1] 4 5 6 [1] 1
- サイクルがある場合は解りにくいので「絵」を描く
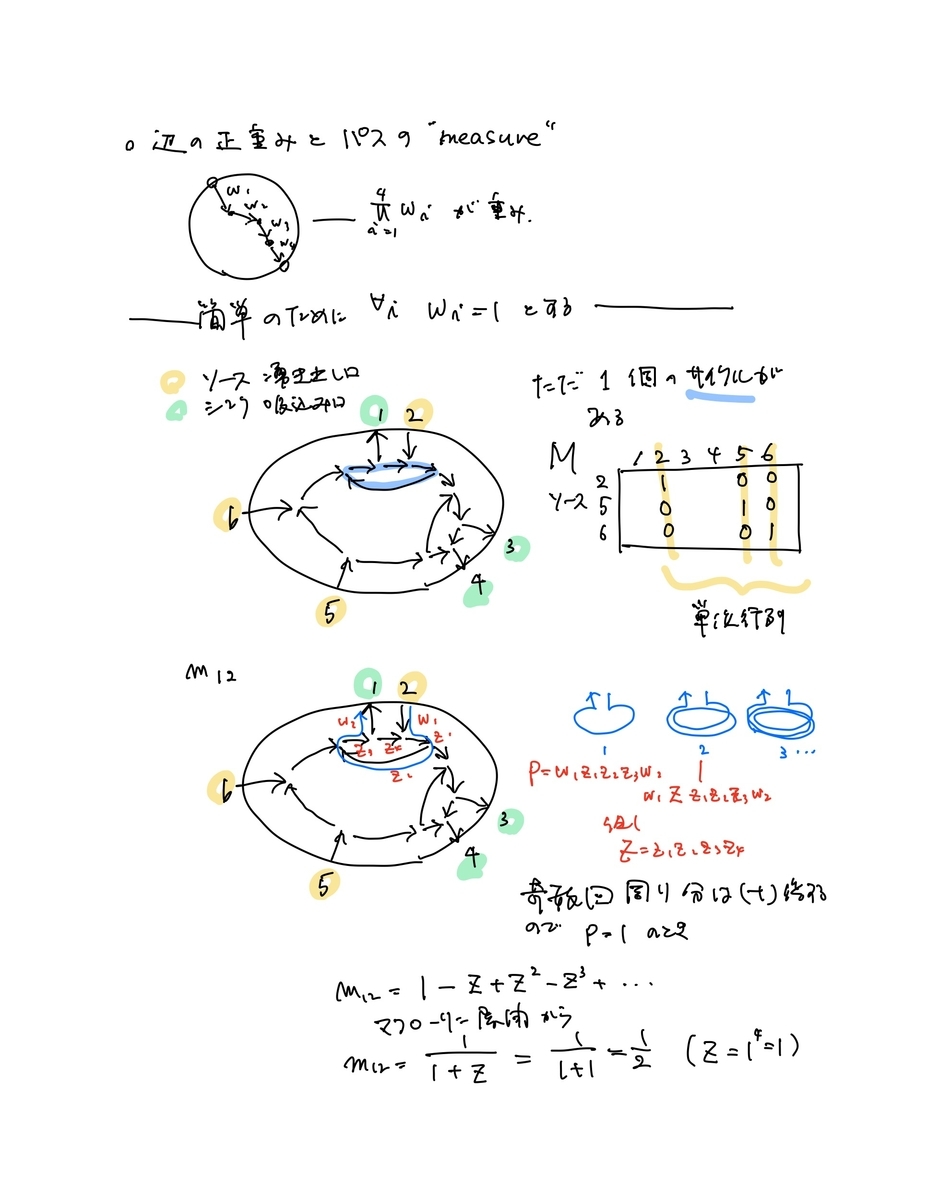
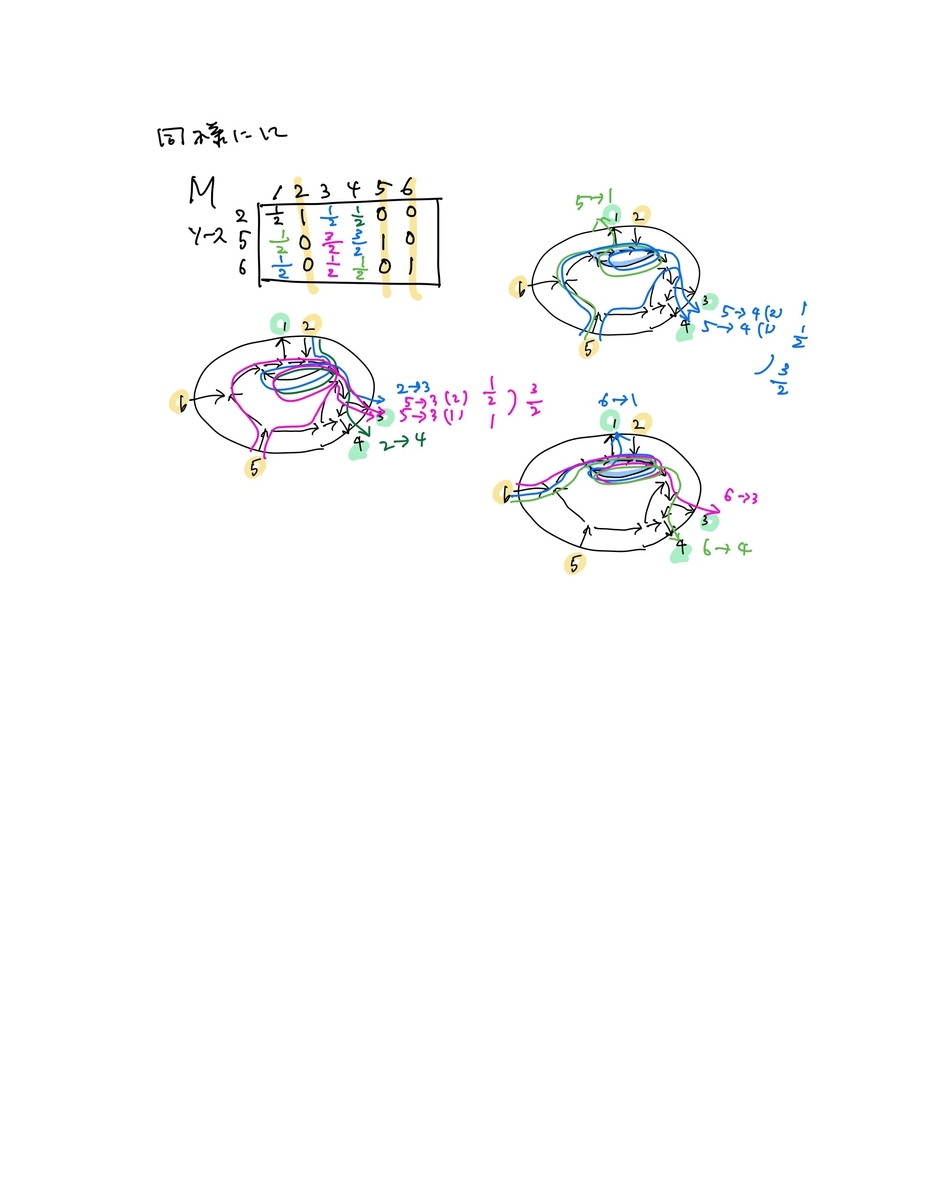
- この行列Mに、頂点ペア間のソース頂点数で符号をつけ、Plucker座標を計算すると、すべて非負
- このPlucker座標(小行列式)は、符号を変える前のMの要素を使って、ソースから行先頂点への矢印の交叉の有無・交叉の数を考慮した式でも計算できることが示せる
D <- matrix(c(1/2,1,1/2,1/2,0,0,1/2,0,3/2,3/2,1,0,1/2,0,1/2,1/2,0,1),byrow=TRUE,ncol=6) D2 <- D * sign(A) # 頂点ペア間のソース数で符号を変える library(gtools) cmb <- combinations(6,3) for(i in 1:length(cmb[,1])){ print("cmb") print(cmb[i,]) print(det(D[,cmb[i,]])) }
> D <- matrix(c(1/2,1,1/2,1/2,0,0,1/2,0,3/2,3/2,1,0,1/2,0,1/2,1/2,0,1),byrow=TRUE,ncol=6) > D[1,2] <- D[2,5] <- D[3,6] <- 1 > D2 <- D * sign(A) # 頂点ペア間のソース数で符号を変える > > library(gtools) > cmb <- combinations(6,3) > for(i in 1:length(cmb[,1])){ + print("cmb") + print(cmb[i,]) + print(det(D2[,cmb[i,]])) + } [1] "cmb" [1] 1 2 3 [1] 0.5 [1] "cmb" [1] 1 2 4 [1] 0.5 [1] "cmb" [1] 1 2 5 [1] 0.5 [1] "cmb" [1] 1 2 6 [1] 0.5 [1] "cmb" [1] 1 3 4 [1] 0 [1] "cmb" [1] 1 3 5 [1] 0.5 [1] "cmb" [1] 1 3 6 [1] 1 [1] "cmb" [1] 1 4 5 [1] 0.5 [1] "cmb" [1] 1 4 6 [1] 1 [1] "cmb" [1] 1 5 6 [1] 0.5 [1] "cmb" [1] 2 3 4 [1] 0 [1] "cmb" [1] 2 3 5 [1] 0.5 [1] "cmb" [1] 2 3 6 [1] 1.5 [1] "cmb" [1] 2 4 5 [1] 0.5 [1] "cmb" [1] 2 4 6 [1] 1.5 [1] "cmb" [1] 2 5 6 [1] 1 [1] "cmb" [1] 3 4 5 [1] 0 [1] "cmb" [1] 3 4 6 [1] 0 [1] "cmb" [1] 3 5 6 [1] 0.5 [1] "cmb" [1] 4 5 6 [1] 0.5
Plabic Graph, Polypositroid and Coxeter Triangulation
https://egunawan.github.io/combinatorics/notes/notes_plabic_graphs2.pdf
arxiv.org
- このペイパーのp18の図は、Plabic graphから組み合わせ三角化・多角形化をしつつ、それをCoxeter membrane座標にしているもの。確かに、正n-gonの頂点ベクトルの組み合わせ和によって頂点座標が指定できること、そのため、三角化・多角形化にて現れる辺の方向が有理的に限定していることを視覚的に確認するRコードは以下
- PolyhedraのCoxeter投影はこちら

n <- 8 theta <- -(1:n)/n * 2 * pi + 7/8 * pi V <- cbind(cos(theta),sin(theta)) V123 <- apply(V[c(1,2,3),],2,sum) V234 <- apply(V[c(2,3,4),],2,sum) V345 <- apply(V[c(3,4,5),],2,sum) V456 <- apply(V[c(4,5,6),],2,sum) V567 <- apply(V[c(5,6,7),],2,sum) V678 <- apply(V[c(6,7,8),],2,sum) V781 <- apply(V[c(7,8,1),],2,sum) V812 <- apply(V[c(8,1,2),],2,sum) V127 <- apply(V[c(1,2,7),],2,sum) V137 <- apply(V[c(1,3,7),],2,sum) V134 <- apply(V[c(1,3,4),],2,sum) V136 <- apply(V[c(1,3,6),],2,sum) V135 <- apply(V[c(1,3,5),],2,sum) V167 <- apply(V[c(1,6,7),],2,sum) V145 <- apply(V[c(1,4,5),],2,sum) V156 <- apply(V[c(1,5,6),],2,sum) Vs <- rbind(V123,V234,V345,V456,V567,V678,V781,V812,V127,V137,V134,V136,V135,V167,V156,V145) plot(Vs,asp=TRUE) s1 <- c(1,2,3,4,5,6,7,8,1,1,1,9,2,3,3,7,6,5,5,4,4,12,13,13,11,12,15,8,10,12,7) s2 <- c(2,3,4,5,6,7,8,1,9,10,11,10,11,11,16,14,14,14,15,15,16,15,15,16,13,13,16,9,14,14,9) segments(Vs[s1,1],Vs[s1,2],Vs[s2,1],Vs[s2,2]) V.lab <- c("123","234","345","456","567","678","178","128","127","137","134","136","135","167","156","145") library(igraph) g <- graph.edgelist(cbind(s1,s2),directed=FALSE) plot(g,layout=Vs,vertex.label=V.lab)
ぱらぱらめくる『量子コンピュータによる機械学習』
![量子コンピュータによる機械学習 [ Maria Schuld ]](https://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/4622/9784320124622.jpg?_ex=128x128 "量子コンピュータによる機械学習 [ Maria Schuld ]")
量子コンピュータによる機械学習 [ Maria Schuld ]
- 価格: 4840 円
- 楽天で詳細を見る
目次
監訳者まえがき
- 機械学習の基礎は高次元データ・線形代数・確率分布の計算であり、それを適切な精度で高速に計算するための近似を発展させてきた
- 量子力学では確率分布関数が対象であり、1つの自由度に無限(次元)の可能性が付随する。この関数を量子ビットに限定しても、ビットを増やすとその組み合わせは指数関数的に増大する。そのことが量子計算の可能性を支えるが、地道に計算すると、逆行列計算、固有値・固有ベクトル計算をすることに対応し、それは、線形代数演算で最も計算量が多いものであることから、「地道な計算」には向いていない
- 計算すると時間がかかるはずだが、現実世界では、ミクロには量子計算が行われつつ、マクロな現象は瞬時に観測されている。この現実世界が行っていることが「量子コンピュータ計算」である
- 量子力学の原理に基づく計算手法を、機械学習の手続きに組み込もうとする試み
- 章立て
まえがき
第1章 はじめに
- 広義の量子機械学習は「機械学習と量子情報の相乗効果を用いたアプローチ全般」
- 本書では狭義の定義「量子コンピュータを用いた機械学習」または「量子の知見に基づいた機械学習」を採用する
- この本が扱う問い
- 1.1 背景
- 量子論の法則を用いなければ述できない計算を実行するコンピュータを量子コンピュータと呼ぶ
- 理論的に量子デバイス・量子コンピュータがデザインされ、実際の作成も進んでいる
- その理論的な量子デバイス上で実装されるアルゴリズムが量子アルゴリズム
- 量子ビットと量子ゲートは、そのような量子デバイスに含まれる。逆に言うと、量子ビット・量子ゲート以外の量子デバイスもある
- 量子コンピュータが行う「演算」は繊細であり、その繊細な状態が首尾一貫していて、正しいことを量子コヒーレンスと呼ぶ
- 量子コヒーレンスを乱さないことは大事だが、乱れることを前提にした対処も求められる。その対処の一つが誤り訂正である
- 誤り訂正は、首尾一貫性の確保であるから、大規模であるほど必要性が大きくなり、量子ビット間の相互作用が多いほど必要性が大きくなる
- 量子デバイス・コンピュータの開発は、大規模・中規模・小規模でそれぞれ進んでいる
- 小規模かつ、ビット間相互作用が少ない量子コンピュータは誤り訂正問題の影響が小さいので、先行している
- したがって、現時点での、実用を意識した量子アルゴリズム開発は、小規模・低相互作用系で解くことができ、かつ、古典アルゴリズムよりも十分に高速化することができるものを標的としている
- 機械学習は「統計学・数学・計算機科学」の交点
- データ量の増大に伴い、機械学習は日常生活・経済活動の中ですでに役割を有している
- 昨今の機械学習の「ブレイクスルー」のほとんどは、「計算能力の向上」「データセット規模の拡大への対応」などの量的改善にとどまる
- ニューラルネットワーク、サポート・ベクターマシン、AdaBoost、深層学習はいずれも理論的には1990年代から知られており、難しい最適化問題を解きつつ、その処理をブラックボックス化している
- 量子計算を機械学習に持ち込むことは質的改変となる可能性がある
- 量子機械学習の4類型
- (データ生成が量子系か古典系か) x (情報処理デバイスが量子系か古典系か) が作る4パターン
- CQアプローチによる教師あり学習
- 1.2 量子コンピュータによる識別
- 例:アダマールゲートにより誘発される量子干渉を用いて、ある種の最近傍法を実装する
- 1.2.1 二乗距離識別機
- 近傍法
- 最近傍法
- 新標本と、既標本との近接度を算出し、最近傍の既標本のラベルを新標本も持つものとする
- k-近傍法
- 既標本のうち、1,2,...,k番に近い標本のラベルの多数決で新標本のラベルを決める
- 重み付き近傍法
- 既標本と新標本の近接度により、各既標本に重みを与え、その重み付き多数決で新標本のラベルを決める。最近傍法、k-近傍法も、重み付き近傍法の重み関数のバリエーションとなる
- 近接度を二乗距離としたとき、「二乗距離法」となる
- 重みを
とすると…
my.sq.dist.classifier <- function(new.x,X,Y,k=1){ Q <- unique(Y) w <-apply( (t(X) - new.x)^2, 2, sum) Pr <- rep(0,length(Q)) for(i in 1:length(Pr)){ tmp <- which(Y==Q[i]) Pr[i] <- sum((1 - 1/k * w[tmp])) } Pr <- Pr/sum(Pr) return(list(Pr=Pr,Class=Q)) } n <- 5 # No. samples p <- 2 # No. features X <- matrix(rnorm(p*n),ncol=p) # No. classes q <- 3 Y <- sample(1:q,n,replace=TRUE) new.x <- rnorm(p) my.sq.dist.classifier(new.x,X,Y)
> my.sq.dist.classifier(new.x,X,Y) $Pr [1] 0.80814006 0.02022597 0.17163397 $Class [1] 1 3 2
1.2.2 アダマール変換による干渉
from sympy.physics.quantum import *
# ↑基本機能のインポート
from sympy.physics.quantum.qubit import Qubit,QubitBra, measure_all, measure_partial
# ↑ブラケットを使えるようにします
from sympy.physics.quantum.gate import X,Y,Z,H,T,S,CNOT,SWAP,HadamardGate
# ↑基本的な量子ゲートを使えるようにします
from sympy.physics.quantum.gate import IdentityGate as I
# ↑恒等変換は省略されないため I と省略できるようにします
from sympy.physics.quantum.dagger import Dagger
from sympy import sqrt
from sympy.physics.quantum.qapply import qapply
# 表・表状態
q1 = Qubit('00')
q1
# 最も右のビットにだけアダマール変換
q2 = H(0) * q1
q2
# この状態q2を測定してみる
q2a = qapply(q2)
measure_all(q2a)
# 状態をq2に変え、そこで観測をせずに、もう一度、片方にだけアダマール変換
q2 = H(0) * q1
q3 = H(0) * q2
# q3を測定してみる
q3a = qapply(q3)
measure_all(q3a)
# ビットの数を増やす
n = 5
q1 = Qubit('0'* n)
q1
# ごちゃごちゃさせておく
q2 = H(0) * H(1) * H(2) * q1
q2
# この状態q2を測定してみる
q2a = qapply(q2)
measure_all(q2a)
- 1.2.3 量子二乗距離識別器
- ステップA:データを単位球面上の点に座標変換する
- ステップB:データ符号化。教師情報と新規標本情報から量子ビット状態(ベクトル)を作る
- ステップC:教師情報と新規標本情報とを区分けしている量子ビットについてアダマール変換する。これにより、教師情報に対応する組み合わせに新規標本情報が「加え」られる
- ステップD:教師情報と新規標本情報とを区分けしている量子ビットを観察し、特定の場合にのみ、下流処理を行うことにする。これにより、新規標本に対応する組み合わせの振幅はゼロのベクトルに変わる
- ステップE:教師情報・新規標本情報の両方に関して、「分類ラベル」に相当する量子ビットを観察する。この観察で0/1のいずれかがどのくらいの割合で観察されるかの推定となる
- データ符号化の後のステップは、C,D,Eの3ステップのみ。これを入力後の処理と見做せば、入力がどんなに多くても、3段階処理で済み、入力データのサイズによらない~定数時間アルゴリズムである、と言う
- これを、二乗距離識別器で、古典的に実行すると以下のようになる
> X <- matrix(c(0.921,0.390,0.141,0.990),byrow=TRUE,ncol=2) > new.x <- c(0.866,0.500) > > Y <- c(1,0) > > my.sq.dist.classifier(new.x,X,Y,k=4) $Pr [1] 0.5519867 0.4480133 $Class [1] 1 0
-
- 対応するSympyの処理は、データ符号化のやり方がわからないが・・・
- ステップB
- 対応するSympyの処理は、データ符号化のやり方がわからないが・・・
# これではだめ!
q1 = (Qubit('0001') * 0.921 + Qubit('0011') * 0.390 + Qubit('0100') * 0.141 + Qubit('0110') * 0.990 + Qubit('1001') * 0.866 + Qubit('1011') * 0.500 + Qubit('1100') * 0.866 + Qubit('1110') * 0.500) * 1/sqrt(4)
q1
-
-
- ステップC
-
q2 = H(3) * q1 q2
- 1.3 本書の構成
第2章 機械学習
- 2.1 推定
- データをモデルに入力として与え、モデルが導き出す結果を出力・推定結果と呼ぶことにする
- 教師アリ学習(識別・回帰、予測)
- 教師ナシ学習(仮説推測)
- 強化学習(ゲーム)
- 2.2 モデル
- 2.3 訓練
- 訓練の目的は最適化問題を解くこと
- 誤差逆伝搬法やボルツマンマシンを利用した深層ニューラルネットワーク学習法は最適化問題を解くための方法
- コスト関数(損失関数と正則化項)
- 確率的勾配降下法
- 訓練の目的は最適化問題を解くこと
- 2.4 機械学習の手法
- 表2.3をよく見よう
- fはモデル関数、pは分布(関数)
- (w,x)は変数とその係数。それらの関係性
- 線形なことは、線形計算(
)で表されている。非線形は、その計算が「非線形関数」になっている
- w(ベクトル)ではなくW(行列)ならば、次元が増減できる
- 層をなしているネットワークは行列の適用の繰り返し
- グラフィカルモデルになると、Wの繰り返しのような構造がなくなり、グラフの構成要素がパラメタを持ち、その総体としての計算になる
- 隠れマルコフモデルはv(t),v(t-1)の関係を持ち込んでいることが式からわかる
- カーネル法は、標本ペアに関して計算する関数を使う方法。変数や隠れ変数を使った関数表現ではなく、標本由来の演算。スカラー値を返すカーネル関数、その束、さらにグラム行列を用いて記述されている
- 線形回帰:行列演算
- 非線形回帰
- ニューラルネットワークは非線形回帰モデルとして働く
- 線形計算結果を非線形モデル関数に処理させる系
- 順伝搬型ニューラルネットワークにおける重みづけ行列の最適化のための勾配計算には誤差逆伝搬法が使われる
- 再帰型ニューラルネットワークは、グラフで言えば完全グラフ。グラフ全体に関して更新を繰り返す。順伝搬型に描きなおすことも可能
- ボルツマンマシンは確率的な再帰型ニューラルネットワークモデル。式が確率密度分布になっている。実際の計算は困難で、制限ボルツマンマシンを用いる
- グラフィカルモデル:ベイジアンネットワーク、隠れマルコフモデル
- カーネル法:カーネル密度推定、k-近傍法、サポートベクターマシン、ガウシアン過程(モデル関数を確率的に選び出す)・・・標本駆動的・・・ノンパラ的・・・
第3章 量子情報入門
- 3.1 量子論の入門
- 3.2 量子計算入門
-
- 量子ビットを使う計算モデルとそうでないモデルとがある(が、量子ビットを使うモデルを基本として、以降の話は進む)
- 「量子コンピュータは、状態の時間変化を正確に制御するn量子ビットの物理的な実装」である
- 「量子コンピュータを使うということは、レーザーの強度や地場などの特定の実験構成で、物理的な観測量の分布を読み取るということ」
- 「量子系の時間発展が、1つまたは2つの量子ビットだけに作用する、量子ゲートと呼ばれるほんの一握りの基本的な「操作」の組み合わせで近似できる」
- 量子ビットは2つの基底状態。その重ね合わせで長さ2のベクトル(ケットベクトル)で表せる
- 2つの基底状態を長さ2の複素ベクトルでも表す
- エンタングルメントないとき(純粋状態)は、複数の量子ビットの集合状態はテンソル積で書ける。エンタングルメントしているとき(混合状態)は、テンソル積で書けない値を取るので、
通りの状態に確率振幅を与えて「足し合わせ」た状態となる
- 純粋状態は[tex:\rho_{純粋} = |\psi> < \psi | = \sum_{i,j=1}^N \alpha_i^* \alpha_j | i>
- 混合状態は
- ちなみに純粋状態を指定する係数の数は
、混合状態のそれは
。この複雑さ~自由度の高さが混合状態の複雑さ
- 観測は
- 量子ゲートはユニタリ変換をすること
- 円タングル回路の例がある。これをSympyで書けるか?
- 関数f(x)の作用の実装
- 「x -> f(x)(とする回路構成は)、一般的にユニタリではないため」別の回路実装「
とされる…(?)
- その実装により、重ね合わせ状態が作られる。重ね合わせ状態を作るということは、2つの状態(f(0)とf(1))とを同時に保持できることを意味し、それが量子コンピューティングのメリットの源泉
- 「x -> f(x)(とする回路構成は)、一般的にユニタリではないため」別の回路実装「
- 3.3 Deutsch-Joszaのアルゴリズム
- 3.4 情報の符号化の方法
- データマイニング・機械学習では情報の符号化の問題が中心になるのに対して、量子計算の領域では話題にならない
- 情報の符号化符号化されるものによっていくつかに分けられる
- 「計算基底符号化 basis encoding」
- 実数を二進法表現し、その01列を量子ビットにに対応させる
- 複数の実数があれば、それをタンデムにつなぐ
- 「振幅符号化 amplitude encoding」
- 量子状態は確率振幅を持つので、振幅情報を量子状態として保持するというアイディアがある。その方法はベクトルでその情報を持つ場合と行列で持つ場合とがある。ただし、いったん量子状態として振幅情報を持つと、振幅情報の変化には、量子状態の変化として実現するしか手がなくなる。言い換えるとユニタリ変換を強制される~線形変換を強制される
- 自由度を確保するために、振幅情報の持ち方に冗長化が必要だったりもする
- 「量子サンプル状態符号化 qsample encoding」
- 量子状態から観測をし、それを繰り返すことで、古典的な確率分布情報が得られる。その変換のこと
- 「ハミルトニアン符号化 dynamic encoding」
- 行列状の情報は、そのような値を持つハミルトニアンとして持つことができる
- ユニタリ行列として持つか、エルミート行列として持つかすれば、量子計算の登場人物とすることができる
- 3.5 需要な量子ルーチン
第4章 量子優位性
- 4.1 学習の計算複雑性
- 漸近的計算複雑性(理論的な概念)、量子コンピュータでは入力の数=量子ビットの数、この入力の数=量子ビットの数を大きくしたときの漸近性を複雑性の指標とする
- 量子コンピュータが「漸近的な実行時間複雑性」を尺度にして古典コンピュータより優れていることを、量子エンハンスメント・量子優位性・量子加速(quantum enhancement, q. advantage, q. speedup)と呼ぶ。量子超越性(q. supremcy)はその優位性が指数関数的なことを指す
- 精度の指標には、推定値と真値の差を定義するノルムが用いられたり、行列を使う推定の場合には行列の条件数(最大特異値(固有値)と最小特異値(固有値)の比)が使われる、行列の条件数 Condition Number がどうしてそのような役割を果たすかについてはこちら
- 確率的に推定するときには、成功確率の低さに応じて、試行回数が増えるので、試行回数の平均(や一定の条件の上限値)なども使われる
- 4.2 サンプル複雑性
- 4.3 モデルの複雑性
- バイアス・バリアンス。自由度。オッカムのカミソリ
第5章 情報の符号化
- 量子計算による機械学習のための枠組み
- 5.1 計算基底符号化
- ビットを組み合わせて、たくさんの場合を作り、そこに入力データとして、重みをもたせていく
- [tex:|D> = \frac{1}{\sqrt{M}} \sum_{m=1}^M |x^m>
- M個の標本のそれぞれの情報が
で、それが確率として
分ずつ合わさったものを、「確率振幅は二乗して『確率』になる」ということを用いて、重みとして
とした式
- M個の標本のそれぞれの情報が
- 入力データの持たせ方の基礎は解った
- 次に、複数の入力データをため込むためにどうするかをVentura-Martinezのやり方を例に説明している
- 記憶用と入力用とを使い分け、どちらが記憶用でどちらが入力用かを判別するビットも保持し、標本の追加に応じて記憶用の状態に相当する確率振幅を更新する
- これとは異なり、並列的にビット列を量子レジスタに読み込む「量子ランダムアクセスメモリ」というデバイスの構成も検討されている
- トフォリゲート
- 量子状態の読み出しは、測定によって実現される
- 測定されるのは、確率的な値。それを繰り返し測定して、比率がわかる
- 量子状態(確率振幅状態)を測定から復元することが「量子状態の読み出し」~量子トモグラフィ
- エンタングルメントがあったりしているときには、ベクトルだけ取り出してもわからない。対角成分以外にも情報のある行列(密度行列)を取り出す必要がある
- 推定と信頼区間。waldの信頼区間とWilsonの信頼区間
> library(binom) Warning message: パッケージ ‘binom’ はバージョン 4.0.5 の R の下で造られました > binom.confint(x = c(2, 4), n = 100, tol = 1e-8) method x n mean lower upper 1 agresti-coull 2 100 0.02000000 0.001095977 0.07441778 2 agresti-coull 4 100 0.04000000 0.012418859 0.10161516 3 asymptotic 2 100 0.02000000 -0.007439496 0.04743950 4 asymptotic 4 100 0.04000000 0.001592707 0.07840729 5 bayes 2 100 0.02475248 0.001548220 0.05487873 6 bayes 4 100 0.04455446 0.009880014 0.08495779 7 cloglog 2 100 0.02000000 0.003866705 0.06362130 8 cloglog 4 100 0.04000000 0.013067378 0.09175206 9 exact 2 100 0.02000000 0.002431337 0.07038393 10 exact 4 100 0.04000000 0.011004494 0.09925716 11 logit 2 100 0.02000000 0.005007519 0.07643178 12 logit 4 100 0.04000000 0.015094076 0.10175601 13 probit 2 100 0.02000000 0.004390455 0.06850351 14 probit 4 100 0.04000000 0.014032309 0.09594809 15 profile 2 100 0.02000000 0.003356435 0.06047940 16 profile 4 100 0.04000000 0.012621438 0.09048300 17 lrt 2 100 0.02000000 0.003353612 0.06047875 18 lrt 4 100 0.04000000 0.012592624 0.09048265 19 prop.test 2 100 0.02000000 0.003471713 0.07736399 20 prop.test 4 100 0.04000000 0.012890866 0.10511152 21 wilson 2 100 0.02000000 0.005501968 0.07001179 22 wilson 4 100 0.04000000 0.015663304 0.09837071
- 5.2 振幅符号化
- NxM個の値を
ビットに符号化する
- いわゆる入力値を確率振幅値(に比例した値)にする
- 量子計算では符号化準備が大変。量子計算の効率化メリットの範囲内で符号化できないと意味がないが、現在、符号化のための手間と、量子化によるメリットとを比較すると、符号化の手間の重さがメリットを宇和待ってしまっている。準備処理を線形時間化できれば・・・という提案手法がある
- Mottonenの提案。複数制御回転ゲート。「効率的にやろう」と考えると、「けちけち」するのが古典的発想。「全部を扱う」のは非効率、と言うのが古典的発想。だが、量子では全部をいじるのは難しくない、全部を逐次的にいじるのは、「全部」を扱うことが量子では軽いので、「逐次処理~線形処理」の重さになる、と、そういう話(か?)
- 量子ビット数に関する効率的な状態準備は、並列化を基礎としたアプローチ、オラクルを基にしたアプローチ、量子ランダムメモリと分けて説明されている
- 量子状態変化は、「全体」を見ているとき、ノルムが1を満足しなければならず、それを満足する変換はユニタリ変換なので、線形。したがって、非線形な処理は本質的に受け付けない。ただし、「測定」によって場合分けすると、知りたいことを測定できるかどうかが確率的に決まり、そのような情報は、ユニタリ変換~線形変換ではないので、非線形な取扱いは測定と絡むらしい
- NxM個の値を
- 5.3 量子サンプル状態符号化
- 古典的な離散確率分布を振幅ベクトルに翻訳する
- N個の離散状態をそれぞれ別個の特徴量変数とみなせば、計算基底を符号化していることになり、それが振幅ベクトルとして実現されているので、振幅符号化とも言える
- 5.4 ハミルトニアン符号化
第6章 推論のための量子計算
- 6.1 線形モデル
- 6.2 カーネル法
- 6.3 確率モデル
第8章 量子モデルを利用した学習
- 8.1 イジング模型の量子力学への拡張
- 8.2 変分回路とニューラルネットワーク
- 8.3 量子力学を利用したモデルに対する他のアプローチ
平面グラフを全域木と完全マッチングに対応させる
- 平面グラフでは
が成り立つ
- この式を変形して
が得られる
- 頂点を1つ取り除き、面も1つ取り除くと、辺の数は、残った頂点の数と残った面の数の和に等しい、と読める
- 「等しい」ということを、「辺に対して、頂点もしくは面を一つ対応させると、完全マッチングさせることができる」と読み替える
- この読み替えが、具体的には、平面グラフから、その頂点・辺・面のすべてを頂点とした平面グラフを構成し、そこから元の頂点と元の面とに対応する頂点を取り除いた後の平面グラフでは、完全マッチングが取れる、ということに対応付けられる
- ただし、取り除く元の頂点は、取り除く元の面を構成する頂点であることが必要
- この構成法において、「取り除く予定の頂点」を根とした有向全域木と、元の平面グラフの双対グラフにおいて「取り除く予定の面」に対応する頂点を根とする有向全域木とが、フォークの相互かみ合わせのようになっていると見立てられることから、全域木とも関係する
- それについて記した文書がこちら:"Trees and matchings"
http://emis.impa.br/EMIS/journals/EJC/Volume_7/PDF/v7i1r25.pdf
2枚の正三角形
- 辺の長さが1の正三角形2枚を貼り合わせる
- 1枚目の正三角形の頂点を
,
,
に取り
- 2枚目の正三角形の頂点を
,
- このとき、1枚目の三角形の2点
と
を結ぶ線分と
- 2枚目の三角形の2点
と
- なす角
との関係が知りたいとする
- 今、特に、
であるような場合(これは、正2k角形の内角)を計算してみる
theta <- (1:10)/(2:11) * pi ct <- cos(theta) plot(ct) cp <- 4/3 * (ct + 1/4) p <- acos(cp) plot(theta,p) p/theta